DB Index - 1
DB Index
인덱스는 실제 SELECT 문을 바꾸지는 않지만, SELECT 문을 빨리 결과가 나올 수 있도록 해주는 데이터베이스 객체 이다
특징 및 장점
- 데이터를 조회할 때 빠르게 접근하도록 도와준다.(항상 그런 것은 아니다)
- 그 결과 해당 쿼리의 부하가 줄어들어서, 결국 시스템 전체의 성능이 향상된다.
- 인덱스가 있던 없던, SELECT 문의 결과는 똑같다.
- 데이터베이스 튜닝 시에 가장 큰 효과를 볼 수 있는 부분도 인덱스이다.
단점
- 지나치게 생성하면 오히려 성능이 떨어질 수 있다.
- 풀 테이블 스캔을 하는 것이 오히려 성능이 좋을 때도 있다.
- 인덱스가 데이터베이스 공간을 차지해서 추가적인 공간이 필요해지는데, 대략 데이터베이스 크기의 10% 정도의 추가 공간이 필요하다.
- 처음 인덱스를 생성하는데 시간이 많이 소요될 수 있다.
- 데이터의 변경 작업(insert, update, delete)이 자주 일어날 경우에는 오히려 성능이 많이 나빠질 수도 있다.
가장 쉬운 예제
책 맨 뒷부분에
찾아보기를 활용하여 찾는 것과 비슷한 개념이다.

인덱스의 종류와 자동 생성
인덱스의 종류
- 클러스터형 인덱스
- 영어 사전 형
- 테이블당 한 개만 생성
- 행 데이터를 인덱스로 지정한 열에 맞춰서 자동 정렬한다.
- 보조 인덱스(비 클러스터형 인덱스) - MySQL 에서는 보조 인덱스라 한다.
- 책 뒤에 <찾아보기>가 있는 일반 책
- 테이블당 여러 개를 생성 할 수 있다.
자동으로 생성되는 인덱스
CREATE TABLE userTbl
(userID char(8) NOT NULL PRIMARY KEY,
name varchar(10) NOT NULL,
birthYear int NOT NULL,
...
)
- 위와 같이
userID를PRIMARY KEY로 지정하면 자동으로userID열에 클러스터형 인덱스가 생성된다.
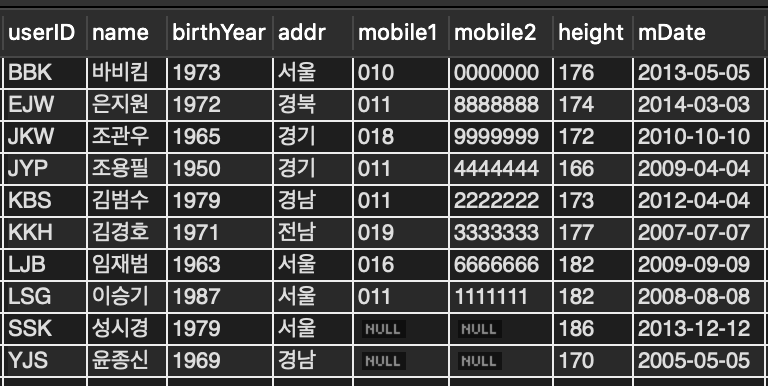
<userID 기준으로 데이터가 정렬 됨을 확인할 수 있다.>
테이블 생성 시에 제약 조건으로
Primary Key또는Unique를 사용하면 인덱스가 자동 생성된다.
- 클러스터형 인덱스가 1개 인 이유는 Primary Key가 1개이기 때문이고,
Unique는 복수개 지정할 수 있는데, 이때 보조 인덱스가 생성된다.
CREATE TABLE tbl1
( a INT PRIMARY KEY,
b INT,
c INT
);
SHOW INDEX FROM tbl1;

<결과를 보았을 때, key_name이 primary 인것을 보아서, 클러스터형 인덱스로 볼 수 있다(예외가 있긴 함)>
CREATE TABLE tbl3
( a INT PRIMARY KEY,
b INT UNIQUE,
c INT UNIQUE,
d INT
);
SHOW INDEX FROM tbl3;

# 보조 인덱스로 만 이루어져 있다.
CREATE TABLE tbl4
( a INT UNIQUE,
b INT UNIQUE,
c INT UNIQUE,
d INT
);
SHOW INDEX FROM tbl4;

CREATE TABLE tbl5
( a INT UNIQUE NOT NULL, # 이럴 경우 a 는 클러스터형 인덱스라 볼 수 있다
b INT UNIQUE,
c INT UNIQUE,
d INT
);
SHOW INDEX FROM tbl5;

위의 a가 클러스터형 인덱스인 증거
INSERT INTO tbl5 values(3, 3, 3, 3);
INSERT INTO tbl5 values(1, 1, 1, 1);
SELECT * FROM tbl5;
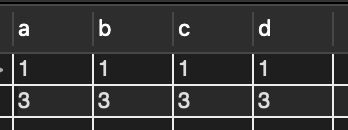
- 1 값이 나중에 들어갔음에도 불구하고, a열 기준으로 정렬이 되어있다.
PRIMARY KEY로 지정한 열은 클러스터형 인덱스가 생성UNIQUE NOT NULL로 지정한 열은 클러스터형 인덱스가 생성UNIQUE( 또는UNIQUE NULL)로 지정한 열은 보조 인덱스가 생성된다.PRIMARY KEY와UNIQUE NOT NULL이 있으면PRIMARY KEY로 지정한 열에 우선 클러스터형 인덱스가 생성된다.